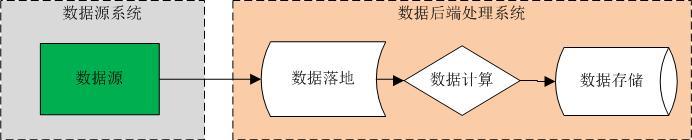
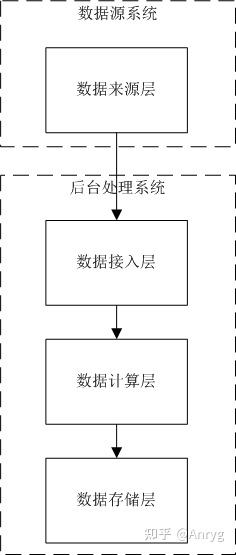
对于任何一个数据处理系统来说,可以简单抽象为2大部分:数据源系统和后台处理系统(为了方便后续文字阐述,这里将数据源部分跟数据处理部分在逻辑上拆分为两个不同的系统)。而后台处理系统都可以简单的抽象划分为3个层次:数据接入层、数据计算处理层和数据存储层。
而数据源作为后台系统的基石,其在设计上又有哪些注意的点呢。有人会说,这有什么好注意的呢,数据过来我就用程序处理呗,处理完成后我就直接写到DB或者直接发送到web页面展示就好了。如果你是这么想的,那只能说明你可能没有参与这个数据接入设计,或者压根没有关注数据是以何种方式流入到系统中的。通常来说,对于一个后台系统来说,数据源的接入大致可以分为2大类:推(push)的方式或者拉(pull)的方式。那又有人会说了,这有什么区别吗,不管是拉的方式还是推的方式我都可以把数据拿过来处理计算啊,虽然是这样,但是你有么有想过,这两种方式的不同直接决定你后续数据处理的方式,频率以及效率的不同。
推方式的主动权在数据源系统侧(即推送数据的程序运行在数据源系统侧),数据源方根据自己数据产生的方式、频率以及数据量来采用一个适合数据源系统的方式将数据推送到后台处理系统,采用这种方式的特点是:数据量、数据格式以及数据提供频率与数据生成方式息息相关,但可能与后台系统需要达到的业务目标并不十分匹配(比如业务需要每10分钟更新一次数据,而数据源每分钟就会产生一次数据)。其中,推这种方式最大的一个特点是数据必须在后台系统先落地,也就是说必须先将数据在一个地方存起来,然后后台处理系统才能进行读取后进行后续的数据处理操作。

由于推送过来的数据必须在后台处理系统先落地,因此就需要一个额外的中间件来充当这个落地的介质,该介质可根据业务场景需求的不同来确定,一般常用的有:消息队列(kafka、rabbitmq等)、数据库(SQL、NOSQL)、文件系统(分布式文件系统、普通文件系统)、NFS、FTP等。
该方式的主动权则掌握在数据处理后台这边(即数据接入程序部署在后台系统这边),对数据获取的频率、数据量和获取方式完全是后台端决定,这种方式是对业务处理最为友好的方式,因为你数据拉取的行为(数据量、拉取频率、拉取方法)可以完全适配你后续的数据处理频率,且可以做到数据接入层与数据计算处理层的无缝衔接,对业务需求非常友好。
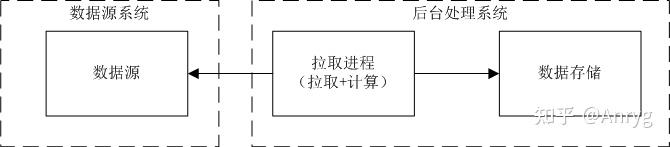
该方式相较于推的方式而言,是可以省去数据落地这一流程的,甚至可以将数据处理的逻辑也合并到拉取进程中,能够大大简化后台处理系统的流程。当然,至于能不能省去需要结合你的实际业务场景来定,这里只是提供了这样一种可行性方案。而至于为什么说对业务友好,原因在于你完全可以根据业务需求对数据的频率和数量要求,来决定数据拉取的频率和拉取量。
以上两种获取数据源的方式,没有绝对的谁好谁坏,只能根据实际业务特点进行权衡而选择。那么一般情况下,我们该如何选择呢?
基于网络安全考虑,外部网络无法直接访问数据源系统的网络,但是数据源系统的网络则可以访问外部网络情况下只能用推;
数据源方生产数据的频率比较随机。比如,数据源方不定期的生成数据且数据量也不固定,为了让后台处理系统第一时间能够完整处理每次产生的数据,需要用推的方式;
基于数据源访问权限考虑,虽然数据源与外部系统网络互通,但是由于数据的访问权限控制,外部系统无法直接读取数据源,这种情况也只能用推的方式;
数据源方众多(比如各种数据采集终端设备),且都是以比较随机的频率提供数据,后台处理系统不太方便通过统一的数据拉取程序来获取数据源,这种情况下也最好用推的方式。
后台处理系统有权限访问数据情况下,数据源方以一个比较固定的频率或者固定的时间节点产生数据;
业务要求必须以固定频率(比如每10分钟)或者固定时间点(比如每天的8:00、12:00、20:00)更新数据;
如果根据实际业务需求发现,两种方式都可以的话,优先选择拉的方式,以此可以达到简化后台处理的复杂度,提高系统稳定性。
综上,两种数据接入的方式分都有着各自的特点,不存在孰优孰劣,具体如何选择完全取决于业务场景需要。
备注:以上内容来自知乎(作者:资深码农、大数据架构工程师)https://zhuanlan.zhihu.com/p/382672887,如有侵权请联系本站管理员处理
